こんにちは。かっぺいです。
AWSのForecastを使う機会が少しあったので、備忘メモとして記載します。
データセットグループの作成
まずは、データセットグループを作成します。
この時点で、予測するドメインを指定します。
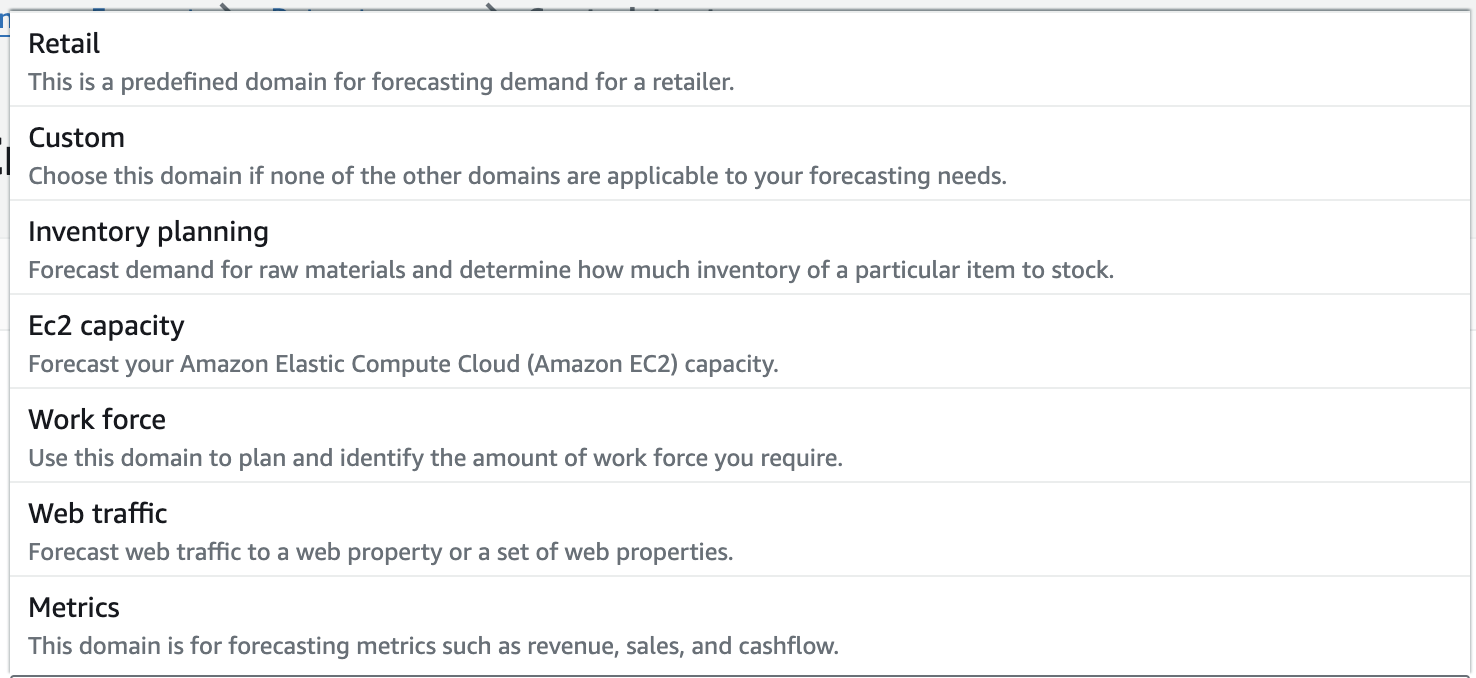
ドメインの選択によって、基本となるターゲットデータの種類が変わります。
売上や需給予測の場合は、MetricsかCustomを選ぶことになると思いますが、今回はCustomで行います。
ターゲット時系列データのインポート
インポートするときに、CSVのレイアウトを指定します。
- Frequency of your data
- 時系列データのサイクルを指定します。1日のデータか時間別のデータかで決まると思います。
必然的に、このサイクルが予測するデータのサイクルとなります。
- 時系列データのサイクルを指定します。1日のデータか時間別のデータかで決まると思います。
- スキーマ
- csvのフィールドレイアウトを指定します
必須となる3種類はあらかじめセットされているので、csvのレイアウトに応じて並び替えてください- timestamp
- 時系列データのフォーマットを指定します
- item_id
- いわゆる商品コード的な数値か文字列になります
これがプライマリのディメンションになります
- いわゆる商品コード的な数値か文字列になります
- target_value
- 学習したい値をfloat形式でセットします
- 追加項目
- 追加で項目を入れることができますが、ディメンションの扱いとなり型はString以外選べません。
※型は画面では選択できるけど、作成時にエラーになります。 - 最終的に、予測データを出力する際にディメンションの数だけデータが出力され、その件数が課金対象となります。
試験段階では、欲張らずに少しずつ行うことをお勧めします。
- 追加で項目を入れることができますが、ディメンションの扱いとなり型はString以外選べません。
- timestamp
- csvのフィールドレイアウトを指定します
- タイムゾーン
- 時系列のタイムゾーンを指定可能ですが、大枠での地域指定となります。
例えば、Asia/Tokyoは選べなくてAsia/Seoulが同じUTC+9となります。- ここのタイムゾーンは選ぶ必要は無い気がします
休日は気象データとしてのタイムゾーンは、関連データで指定することになります
- ここのタイムゾーンは選ぶ必要は無い気がします
- 時系列のタイムゾーンを指定可能ですが、大枠での地域指定となります。
- S3の場所とIAMロール
関連データセット
時系列データセットと同じ感じで、スキーマ情報を登録します
- timestampとitem_id
- 時系列データセットと関連づけるための項目
- 時系列データセットで、追加のディメンションを設定した場合は関連データセットにも同じディメンションを設定します
- 関連データ
- 関連データを設定します
型は自由に設定可能です。 - GeoLocation情報をセットすることで、タイムゾーンと気象データの場所として使用することが可能です。
- 2024年時点では、気象データは利用場所に制限があるので日本で利用する場合にはGeoLocationは必要ないと思います
- 関連データを設定します
- S3の場所とIAMロール
インポートするCSVデータの注意点
Forecast料金計算
インポートするCSVデータの課金単位は、データサイズです。関連データの数と時系列データの数は大きくてもあまり金額的には問題ないかと思います。
投入するデータサイズによって、学習の計算時間は長くなるかもしれませんが、おそらくは数時間のコンピュート時間で済むと思うので、金額としての比重はあまり大きくありません。
データの予測は、予測したいサイクル数と分位数の数で変動しますが、料金計算の単位が予測するデータの件数になっているので注意が必要です。
ディメンションの数を多くすると、予測するデータの件数が大きくなるので料金比重が大きくなります。
特に、試作段階でディメンションを大きく取ってしまうと、使い物にならない予測データのために大金を払う結果になります。
インポート後のデータの確認
インポート後のデータの確認手段はあまりありません。
データのエントリー数、ユニーク数、最小値、最大値、標準偏差、エラー件数、無効件数を知れるだけです。
欠損データの補完
欠損データについては、学習を実行する際にオプションとして取り扱い方を指定することができます。
ただし、実際にどのような値が補完データとして採用されているかは知る手段がありません。
機械学習は、投入するデータによって結果が大きく左右されるので、補完データはインポートする前に自前で処理する方がコントロールしやすい気がします。
データのクレンジング
欠損データの補完と同様ですが、データのばらつきが大きかったりするとMLは結果が良くありません。
また、ディメンションとして利用しない場合は、文字列データは関連データとしては扱いにくいので数値化しておくなど、データのクレンジングを前処理として行なっておくことをお勧めします。
Forecastでは、クレンジングしないcsvを投入して結果を出力することは可能ですが、全く予測としては使えないデータを出力して、料金だけ発生するということが起こります。
最後に
AWS ForecastはSaaS的なMLサービスとなるため、インポート後の処理はほぼブラックボックスになっていて、コントロールはあまりできません。
インポートするデータで結果がほぼ決まってくるので、インポートするcsvで学習結果をコントロールする形になるかと思います。
